

“So, how’s it going with Databricks? I’ve heard about it here and there, but it seems like a lot has changed, right?”
That’s the question a colleague asked me a couple of days ago. Today, while going through the “EDW-ETL Migration to the Data Intelligence Platform Partner Presales Badge” course, I had the chance to reflect more on the topic.
![]()
Databricks Then and Now
What were “Databricks” in the past, and what are “Databricks” now? According to Databricks materials, 74% of enterprises have already deployed a Lakehouse architecture. Meanwhile, I’ve spent 15 years in data — much of it with SQL Server — and last year, I became deeply active in the Databricks Community. That transition gives me a perspective I underestimated when I was younger.
- I started my journey with SQL Server at a time when SSIS, SSRS, and SSAS fulfilled most BI needs, delivering “classic” data warehouse solutions.
- About seven years ago, the focus shifted to cloud data lakes (often jokingly called data swamps).
- Four years ago, I began using Databricks. It wasn’t smooth sailing initially, and I faced a few key hurdles:
1. Cluster Start Time
Coming from SQL Server, I was used to immediate responses. Waiting five minutes for a cluster to start felt like an eternity — and was even harder to explain to business analysts:
“Why are my queries not running? Did it crash? What do I do now?”
2. Extra Maintenance Commands
SQL Server rarely needed manual steps like REFRESH, OPTIMIZE, or VACUUM. Databricks introduced these housekeeping tasks, which felt foreign to a traditional SQL developer.
3. A Lot of Python
I was accustomed to writing mostly SQL. Seeing so much Python code in data pipelines required me to learn new skills and adapt my workflow.
Yet today, everyone seems to be using Databricks. I’ve started writing articles with greater commitment to the platform, and Databricks is confident enough to refer to some competitors as “legacy data warehouse solutions.” The journey must have been long for Databricks to become such a recognized market leader, and the course gave me a good look at how they addressed earlier shortcomings.
Pain Points of Legacy EDWs
According to the course, three main issues typically affect older enterprise data warehouses:
- Specialized Technical Skills
Legacy EDWs usually demand niche expertise, limiting the talent pool and forcing organizations to rely on a small set of specialists. - Complex Infrastructure
On-prem environments or older data platforms can be slow to scale and challenging to upgrade, leading to frequent disruptions and drawn-out change cycles. - Slow Performance at Scale
As data volumes grow, query times often rise exponentially, frustrating both engineers and analysts.
Databricks’ Core Solutions
The course materials highlight three key answers from Databricks to these legacy challenges:
- User Experiences with Natural Language and Data Intelligence
Databricks aims to democratize data so that even non-technical users can query information in a more intuitive, natural language format. - Predictive Optimizations for Infrastructure
Intelligent, automated management and tuning reduce the need for manual housekeeping (e.g., vacuum or optimize schedules). - World-Class Price Performance
Databricks claims a highly competitive total cost of ownership (TCO), especially when leveraging open formats like Delta Lake.
From my perspective, that’s just part of the story. A single slide in the course showcased all the new features released in the last 18 months: liquid clustering (replacing traditional partitioning), serverless options, predictive optimization, Gen AI support, and a flood of new SQL functions. It’s remarkable how much has changed to address earlier friction points.
Addressing Earlier Frictions
Reflecting on what I struggled with initially:
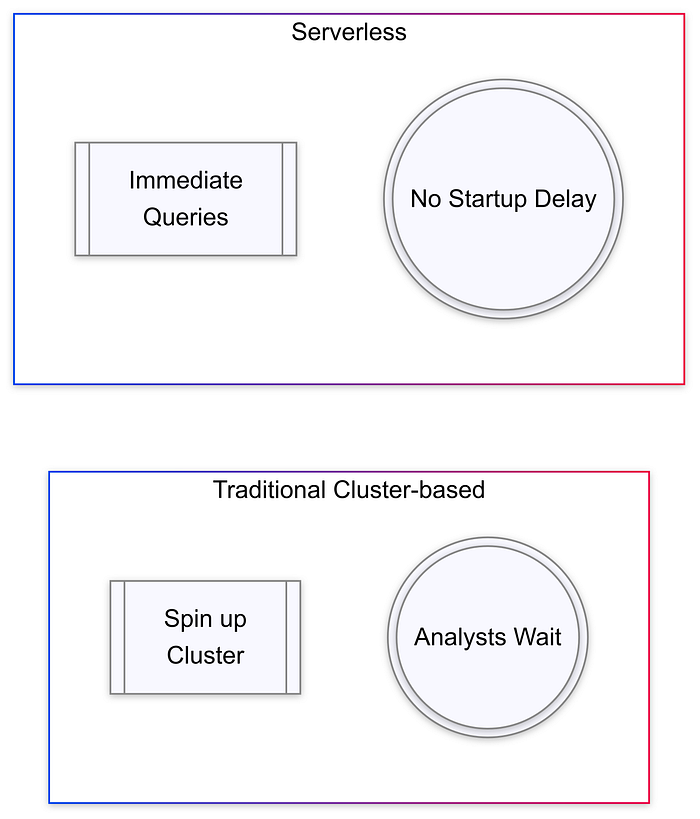
- Cluster Start Time
Serverless SQL Warehouses solve this by providing immediate query execution, mimicking the experience of older, non-distributed solutions.
- Predictive Optimization Covering
OPTIMIZEandVACUUM
Databricks now automatically optimizes and vacuums under certain conditions, drastically reducing manual maintenance. - SQL-Friendly Approach
There’s now robust support for SQL. In one of my recent projects, we wrote about 90% of the Silver and Gold layers in SQL; with the latest improvements, we could likely push that closer to 100%.
AI Everywhere
Databricks goes beyond “matching older solutions.” AI permeates almost every feature. The AI assistant helps with daily coding tasks — something I use nearly all the time. According to MIT Sloan research, generative AI can improve productivity for skilled professionals by up to 40%. Within Databricks, these AI features streamline tasks like aligning SQL or mapping transformations between sources and targets.
My Merge Formatting Obsession
I’m obsessed with neat SQL formatting. For example, imagine a MERGE statement (enabled by the Delta format) mapping source to target columns. I like aligning all the equals signs on one vertical line so I can instantly see the difference between source and target columns. Now, Databricks AI can:
- Intelligently map columns even if names differ
- Respect my “crazy” formatting demands, saving me an hour of manual alignment
EDW-to-Lakehouse Migration Phases
Here’s an outline from the course on how to migrate from a legacy EDW to Databricks:
- Discovery & Assessment
Identify data sources or ETL processes that would benefit most from modernization. Collect baseline metrics on performance and resource usage. - Planning
Define success criteria (shorter query times, lower maintenance costs, simpler governance) and chart a timeline for incremental adoption. - Implementation
Migrate selected datasets to Delta Lake, enabling serverless queries and letting Databricks automate ongoing optimizations. Monitor performance gains as you expand coverage. - Validation & Rollout
Test thoroughly to ensure data consistency and performance improvements. Gather feedback from relevant teams and make iterative adjustments.
Regardless of the data modeling approach — classic dimensional modeling (dimensions/facts), Data Vault (hubs/satellites), or newer paradigms like Data Mesh — Databricks can handle it.
Why It Matters Enterprise-Wide
1. Cost Efficiency
Leveraging open formats and automated scaling can reduce overall ownership costs compared to older EDW architectures with hefty licensing fees.
2. Time-to-Insight
Faster queries and automation of repetitive tasks let both technical and non-technical staff focus on generating valuable insights instead of managing infrastructure.
3. Future-Proofing
A Lakehouse architecture is inherently adaptable, supporting real-time analytics and advanced AI. Once data is in place, moving into machine learning or Generative AI becomes a natural extension — an outcome also highlighted at Databricks’ recent Data and AI conferences.
Final Thoughts
After completing the “EDW-ETL Migration to the Data Intelligence Platform Partner Presales Badge” course, I’m convinced Databricks has evolved far beyond its original cluster-based model to become a data and AI powerhouse. If you’re wrestling with an older EDW that can’t keep up with modern demands, this phased migration approach — bolstered by serverless execution, predictive optimizations, and deep SQL support — might be the solution.
As I see it, moving to Databricks isn’t merely switching platforms; it’s a strategic shift that aligns with where data and AI are heading next.
References
Partner Training — EDW-ETL Migration to the Data Intelligence Platform Partner Presales Badge